KEY CONCEPTS
•
Transitioning from reactive to proactive maintenance is challenging but necessary; organizations that succeed see fewer equipment failures, lower maintenance costs and longer asset life.
•
Resistance, uncertainty and eventual buy-in are common phases during the transition, and success relies heavily on clear communication, stakeholder involvement, targeted pilot programs and ongoing training.
•
Emerging technologies such as IoT sensors, AI analytics, digital twins and visualization tools are revolutionizing condition monitoring, enabling earlier detection of equipment issues, better decision-making and more efficient maintenance planning.
In most cases, repairing equipment after failure can cost three to five times as much as repairing/maintaining it proactively. However, many organizations do not currently make the investments required to maintain equipment using this approach. As a result, they continue to experience ever-increasing maintenance costs and unplanned equipment downtime. While most maintenance and reliability professionals know this, it can often be challenging to make the case with management to shift the approach because of the upfront cost.
The terms preventive, predictive and proactive are often used interchangeably, but technically they are different strategies. Al Yates, vice president at Eurofins TestOil, explains, “Preventive maintenance follows a set schedule to avoid failures, predictive maintenance uses real-time data to forecast issues before they happen, and proactive maintenance addresses root causes to prevent failures altogether. These strategies are often combined to extend equipment life.”
Not everyone defines preventive, predictive and proactive this way, but what these strategies have in common is that they catch potential issues before they cause unplanned downtime—in other words, they are not reactive.
Proactive maintenance can be challenging and costly to implement. When a piece of equipment is less critical, has redundancy, is relatively inexpensive and/or quick to fix the proactive approach is generally not required and does not deliver solid return on investment (ROI). In other cases, the investment is worth it, saving a significant amount of money in terms of repair/replacement and lost production. Given all this, it’s important to know when to apply a proactive approach and to make it a point to be up to date on the latest technologies and strategies that support it.
Proactive maintenance can be as simple as greasing bearings weekly or as complex as installing live, wirelessly connected devices to monitor a network of signals and process that data using artificial intelligence (AI) models to produce maintenance recommendations. There are varying degrees to which equipment can be maintained proactively, and it’s up to management to find that balance.
Yates observes, “Proactive maintenance helps prevent unplanned downtime, reduces emergency repair costs and extends asset life by identifying and remediating issues early before they cause damage. In contrast with reactive maintenance, which waits for failure, proactive maintenance leads to more efficient operations and improved management of resources.”
Making the transition to proactive maintenance typically involves a number of hurdles such as developing the program, prioritizing equipment, choosing technologies and getting everyone on board for change. These challenges are not insurmountable.
Trends
The trend
is shifting toward proactive maintenance, driven mainly by advancements in Internet of Things (IoT), sensors and AI. IoT refers to a network of physical devices—in this case sensors—connected to the internet, enabling them to collect, exchange and act on data. While more organizations are recognizing the value of proactive maintenance and moving in that direction, it has been a gradual transition.
Tolu Ajele, supervisor fleet maintenance engineering at BC Transit, explains, “Increasing our proactive maintenance is a top priority as currently we are more reactive. Right now, our internal data shows that approximately 30% of our fleet maintenance time is spent on proactive work.”
Most organizations still tend to be more reactive than proactive when it comes to equipment maintenance—especially in industries where maintenance hasn’t traditionally been prioritized or where cost constraints are a factor. Reactive maintenance is often the default because it appears to be more cost-effective in the short term and doesn’t require upfront investment in planning or monitoring systems. However, this approach usually leads to more unplanned downtime, increased long-term costs and reduced equipment life.
On the other hand, organizations that adopt a proactive maintenance strategy—such as scheduled inspections, regular condition monitoring and predictive analytics—typically experience lower overall maintenance costs, fewer unexpected failures and improved operational efficiency
(see Figure 1).
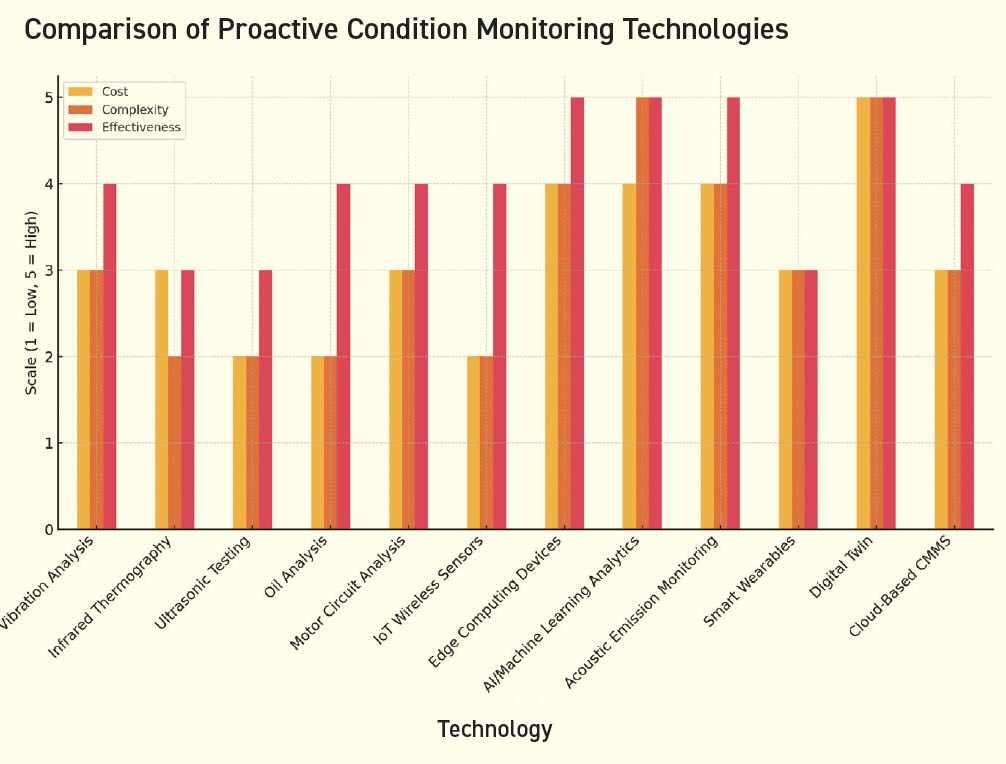 Figure 1. Proactive equipment monitoring strategy: quick glance summary.
Figure 1. Proactive equipment monitoring strategy: quick glance summary.
Jory Maccan, fleet reliability analyst at Imperial’s Kearl Oilsands, notes, “There are certain items that we are really proactive with, in trying to get ahead of maintenance, but like any organization, change is hard and often takes time. People often fall back into reactive ways.”
Daniel Paul, senior reliability engineer at Centerra Gold (who recently started working with the company), says that he is much more proactive than reactive. “We are currently auditing our preventive maintenance program to see if/what we are over preventive maintaining so we can ensure we maximize our tradesmen’s time on the correct tasks,” he says.
Implementation challenges for management
When management tries to implement a more proactive maintenance approach, the response they can expect will generally fall into three progressive categories—resistance, uncertainty and eventual buy-in—but the end response depends on how well the change is communicated and managed.
1. Initial resistance. Resistance often begins at the frontline, where maintenance teams, accustomed to reactive run-to-failure practices, may be hesitant to change. Operational teams can also be slow to adapt, since scheduled maintenance is sometimes seen as an interruption to productivity and a source of unnecessary downtime. From a financial standpoint, proactive strategies often come with upfront costs—such as investing in sensors, computerized maintenance management systems (CMMS) and predictive analytics—which can raise concerns about ROI.
2. Uncertainty and skepticism. Employees may initially question the value and feasibility of adopting a proactive approach, especially if they are unclear about how new processes, metrics and responsibilities will impact their roles. There can be confusion during the transition, and some may even worry that the new systems are a means of micromanagement or a precursor to staff reductions.
3. Gradual acceptance and buy-in. As the benefits of proactive maintenance become apparent, i.e., reduced equipment failures, increased uptime, improved safety and cost savings, support typically begins to grow. This shift is often driven by consistent communication about the reasons behind the change and the goals it aims to achieve. Involving the reliability team in planning and decision-making encourages ownership and trust, while training and hands-on support ensure that employees are comfortable with the new tools and processes
(see Five Hallmarks of Truly Useful Proactive Maintenance Tools).

Five hallmarks of truly useful proactive maintenance tools
1.
Early detection of failures
2.
Ease of deployment (non-disruptive, minimal training)
3.
Scalability (works across many asset types)
4.
Data integration (works well with existing systems)
5.
ROI is straightforward
Ajele observes, “One of the unique challenges that we have is that we are managing a fleet of over 1,100 vehicles across 57 transit systems, and each system is operated by a third-party contractor. So, when it comes to standardization, there is an added layer of complexity that we need to navigate in order to get the level of consistency we need in terms of how work is being done and what data we receive, as well as how and when. Clear communication both ways is even more important, and a strong process for support and accountability for all locations is essential. It also presents challenges when it comes to maintenance practices because the fleets operate in a variety of environments throughout the province; sometimes one size does not fit all.”
The reality of changing from reactive to proactive
In the real world, the process of transitioning from a reactive to a proactive maintenance strategy has its challenges. Maccan explains one of the primary issues—avoiding data overload. “We are making great strides in trying to identify the data that is automatically collected by our equipment and trying to learn how to manipulate it and package it into a useful source of information without overwhelming volume or complexity,” he explains. “We have a lot of buy-in from management to move to more in-depth condition monitoring activities that will drive a large part of our maintenance activities.
“Management is proactive in focusing effort on identifying and taking hold of opportunities to leverage data that already exists, as well as create new data from inputs we already have, but don’t utilize effectively. We have looked objectively at what our systems collect and generate—in terms of performance data—and how we can use that data to make informed maintenance decisions before functional failures occur. One of the hardest aspects is trying to find the tools, experienced people and equipment/software to make good use of the data, that will lead to sound decisions.”
Ajele explains the change process at BC Transit. “The creation of the standard jobs program in our organization was an initiative that launched in 2022,” he says. “This program introduced new documentation to standardize work packages and ensure consistency across the many different shops and staffs in each location. It also provided clear expectations around what components should be serviced and proactively replaced when certain work was being done.”
He continues, “It began with a trial on a portion of our fleet in a few locations throughout the province. The implementation included working with a small team to clearly define the goals of the program, and the plan to get there; in-person presentations with mechanics and other key staff involved to explain the program and its benefits; and regular engagement, reporting and follow-up to support the change management process. We worked closely with the trial locations to collect and implement feedback to improve documentation and other parts of the program.”
Finally, after trialing it for a year, BC Transit launched the program across all affected locations. While there was some resistance—mainly arising from differing opinions regarding what items should be replaced and when—overall the organization demonstrated fairly wide acceptance of the program. The key was making the benefits clear. By showing the rationale behind the program and how it would lead to less reactive maintenance and operational interruptions, most employees concluded that it made sense.
Shifting from reactive to proactive maintenance is a strategic, multi-phase process that requires buy-in, planning and culture change.
“When you are in a reactive mode it is hard to switch into a proactive mode because items have been left unchecked for a long time, and you will continue to have random failures which takes away from your planned schedule,” Paul observes. “We did this at another company I worked for and we made it work by starting small and simple. Rather than having people go out with huge checklists that would most likely come back with numerous items that need to be fixed (which would just overload the system and cause it to fail before it even started), we started with basic inspections.”
He continues, “It took a while (approximately six months), but we did start to see fewer and fewer failures which allowed us to schedule more and more preventive maintenance and inspection tasks. As we got over the initial hill of failures, we were able to start to refine the inspection tours and add more specific data points where needed. It is always easier to add points to an inspection tour than try to remove unneeded ones (in my experience).”
Yates cautions, “Companies may hesitate to undertake this process because of limited internal resources or increased upfront costs. Others may struggle with change management or believe their current reactive strategy is ‘good enough’ until a costly failure proves otherwise.”
Proactive condition monitoring technologies
Some companies are using visualization tools that allow them to manipulate, aggregate and display huge data sets in a way that can be easily digested by employees. Some of the tools being developed will monitor data sets and operating conditions to trigger alerts when combinations of data present in a certain way—high exhaust temperatures paired with intake restriction, for example. The alert might trigger a work event to change air filters automatically without the intervention of a data analyst, whereas only one of those inputs without the other might trigger a different response.
“We can then do the same thing with hundreds of different sensors to come to a most likely root cause of an anomaly,” Maccan says. “Automation of the analysis for common data outputs will be the next step ahead in the evolution of proactive maintenance but will require the tuning of both the inputs as well as the standard response. I firmly believe that AI will develop into an excellent data analyst that will be able to pick up correlations between many hundreds of variables, and that the maintenance industry will see great strides in this direction in the next three to five years.”
He adds, “I think that the visualization tools have been a game changer for us—being able to look at historical short-term readings, overlay and manipulate them quickly and easily has allowed us to participate in the troubleshooting before the machine is even removed from production. Being able to look at the operating data in nearly real time allows us to test theories and look at other parameters while the machine is still in production and the problem is still active. In the recent past this would have been accomplished after a production unit was shut down by downloading the loggers and manually going line by line through logged data sets.”
Ajele points to two proactive technologies and strategies: engine coolant testing and utilizing the standard jobs program to trigger proactive replacements for certain components. “For coolant testing we were previously changing coolant on a kilometer-based interval regardless of its condition,” he observes. “We moved to a standard coolant across the entire fleet and implemented a testing-based coolant change process. This introduced coolant testing on a regular frequency. The results of the testing determined if a coolant change was required or not. As long as the test was passed, the vehicle could continue operating with that coolant until the next test. Also, introducing the standard jobs program provided us with a robust method to clarify expectations around any work that we wanted done proactively given a specific opportunity.
“Both of these examples, engine coolant testing and the standard jobs program, have been very successful, but there have been two very obvious benefits of the coolant testing program that we have seen. The first was successfully catching vehicles that had degraded coolant at an early stage and being able to address the issue before any engine damage had occurred. The issue was able to be flagged, investigated and the root cause addressed to prevent future occurrences. The second notable benefit was a reduction in unnecessary coolant replacements. And then, rather than having a scheduled service regardless of whether it was required, we are now able to utilize the intended life of the coolant as long as it continues performing (which is verified by regular testing). This resulted in reducing time in our preventive maintenance program and less consumption of coolant.”
Paul says, “One strategy is to implement an infrared thermography (IR) program for some of the process piping and electrical equipment as well as enhance a non-destructive testing (NDT) program in house. Another option is expanding an ultrasonic greasing program so that we can get more precise greasing done.
“I would say that all three of the items (IR, NDT and ultrasonic testing) are equally successful. The IR scans are allowing us to see the internal wear on our lined process piping, which allows us to replace the sections before they rupture. The ultrasonic greasing is allowing us to ensure we add the amount of grease that each bearing requires instead of just a calculation, and the NDT program (which is largely ultrasonic testing) is allowing us to track the wear on our conveyor belts and lined rollers so that we can more accurately predict the lifecycles and also pinpoint when items aren’t meeting the proper runtime.”
Traits of effective and proactive condition monitoring technologies
Proactive condition monitoring technologies have advanced significantly in recent years because of IoT, AI, wireless sensors and cloud computing
(see Six Established Condition Monitoring Technologies). Both established and emerging condition monitoring technologies are facilitating the transition for companies that want to move from reactive to predictive maintenance
(see Six Newer and Emerging Condition Monitoring Technologies).

Six established condition monitoring technologiesA
Al Yates, vice president of Eurofins TestOil, says that lab oil analysis is crucial in order to provide a clear picture. “The other technologies are great, but they don’t give you the complete picture the way oil analysis does. There are many other technologies that are complementary to oil analysis, but oil analysis is still the foundation.”
•
Oil analysis. Examines lubricant for contamination, viscosity breakdown or wear particles. It can predict internal component wear early on.
•
Filter debris analysis. Analyzes debris trapped in the filter that is not detected by oil analysis.
•
Vibration analysis. Detects imbalance, misalignment, looseness or bearing failures. It is now often wireless and connected to real-time dashboards.
•
Infrared thermography. Uses thermal imaging to detect overheating in bearings, motors and electrical systems. It doesn’t require contact and is useful for identifying hidden faults.
•
Acoustic emission monitoring. Flags high-frequency stress waves that may indicate deformation, cracks or friction. It is especially good at detecting early-stage structural fatigue or bearing damage.
•
Ultrasonic testing. Detects leaks, electrical arcing or bearing issues before they fail. Primary applications are lubrication monitoring and compressed air systems.
A. These have been available for a decade or more and are widely used.

Six newer and emerging condition monitoring technologiesB
•
IoT-based wireless sensors. Small, battery-powered sensors that monitor temperature, vibration, humidity, RPM, etc. They communicate via Bluetooth, Long Range Wide Area Network (LoRaWAN) or WiFi to cloud-based platforms and are easy to retrofit on existing equipment. LoRaWAN is a low-power, long-range wireless communication protocol designed for connecting battery-operated devices to the internet in wide area networks, ideal for IoT applications.
•
Edge computing devices. They analyze sensor data locally (at the “edge”) rather than sending it to the cloud. This enables real-time anomaly detection with less latency. Edge computing refers to processing data near the source of generation instead of relying on a centralized cloud, enabling faster response times and reduced bandwidth use. Sensors are an example.
•
AI and ML analytics. Uses historical and live data to predict failures and suggest maintenance actions. Results improve over time with pattern recognition and adaptive learning.
•
Smart wearables. Augmented reality (AR) glasses, smart helmets or wearable sensors that support guided inspections or remote diagnostics. They are especially useful in hazardous or hard-to-reach environments.
•
Digital twin technology. Creates a virtual/simulated model of the machine that replicates real-time behavior using live data. It is capable of simulating wear, stress and operational conditions.
•
Cloud-based computerized maintenance management system (CMMS) with predictive plug-ins. Modern CMMS platforms integrate with sensors and AI tools. They deliver condition-based alerts, scheduling and root cause analysis.
B. These use smart sensors, AI and remote/cloud access for proactive insights.
The most successful condition monitoring technologies—in terms of real-world impact, ROI and widespread adoption—tend to be the ones that balance effectiveness, scalability and ease of use (see Figure 2). These include:
1. IoT wireless sensors. They are easy to install on legacy equipment, relatively affordable and provide real-time monitoring without disrupting operations. They are also scalable, non-invasive and support multiple metrics (temp, vibration, humidity, etc.).
2. AI/machine learning (ML) analytics. They transform raw data into predictive insights by identifying patterns that technicians often miss. They are a reliable way to make data-driven decisions (accuracy improves over time) and reduce unnecessary maintenance. AI/ML analytics are especially powerful when integrated with IoT or CMMS platforms.
3. Vibration analysis. This is a reliable, proven method for detecting issues in rotating machinery (motors, fans, pumps). Especially valuable applications include manufacturing, heating, ventilation and air conditioning (HVAC) and utilities. Vibration analysis also pairs well with wireless sensors.
4. Cloud-based CMMS with predictive plug-ins. This centralizes data, automates scheduling and enables condition-based triggers. The technology is easy to adopt, promotes visibility across teams and integrates well with other predictive maintenance tools—creating a foundation for a scalable, proactive maintenance program.
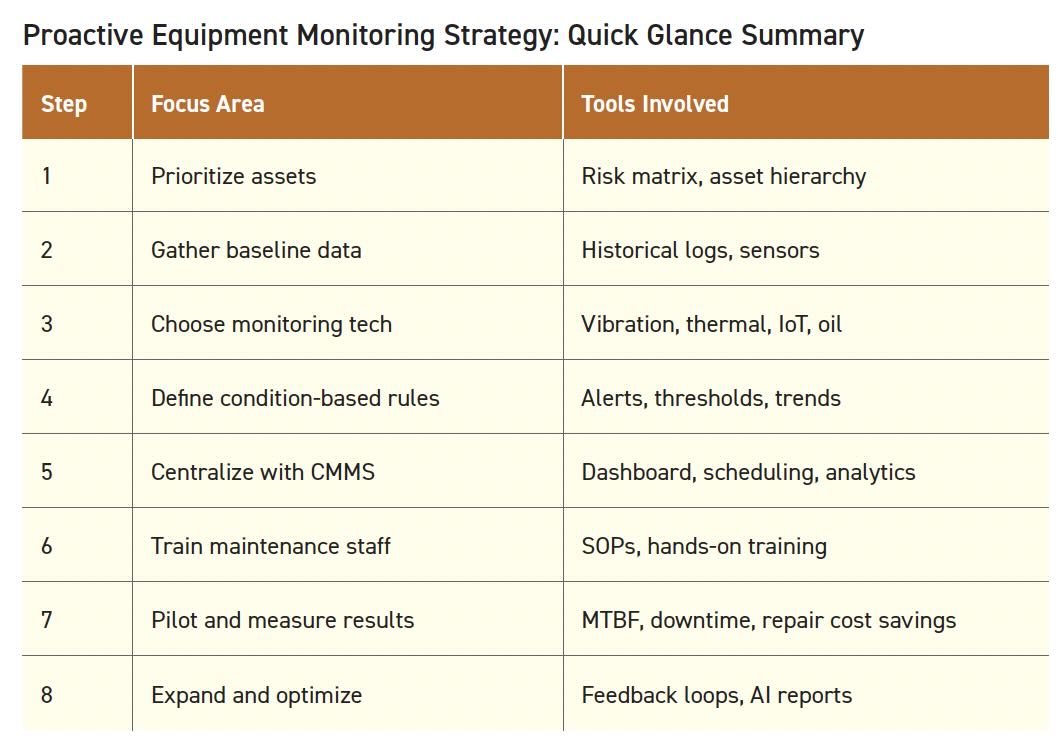 Figure 2. Comparison of proactive condition monitoring technologies.
Figure 2. Comparison of proactive condition monitoring technologies.
Conclusion
Ajele concludes, “We have a lot of work ahead of us to continue growing in our proactive work. A central piece of this is the collection and analysis of data from our fleet to help guide our efforts. We have been working aggressively to maximize the use of data available from vehicles as well as our maintenance workorder history to understand trends, key issues and to set goals for improvement.”
Maccan is convinced that condition monitoring is on the cusp of another data revolution. “When we look back in 20 years, the present day will look archaic on the AI front as far as maintenance management is concerned,” he notes. “I propose that those companies that embark on the AI adventure first will reap the greatest benefits, but they must recognize that during our phase of learning how to interact with AI, we must double and triple check everything. We must also recognize that there will be mistakes made, and the maintenance managers of today will need to stay engaged and alert to limit the damaging effects of mistakes made during the process of learning how to leverage and benefit from the power of AI.”