Complexity in ISFA (in-service fluid analysis): Part XXIV
Jack Poley | TLT On Condition Monitoring September 2015
When it comes to partial data, fix what you can and deal with the rest.

www.canstockphoto.com
LAST ISSUE I NOTED THAT THERE IS A SCARCITY OF DATABASES that have been maintained in a sufficiently meticulous manner such that they are optimized for ISFA. In such instances ISFA evaluations are thwarted with alarming regularity, resulting in misanalyzed data—yes, money left on the table.
And since ISFA evaluations are increasingly being conducted via Intelligent Agents, it is important to standardize terminology to the utmost, beginning with manufacturers of machinery and lubricants.
There are two logical ways to mitigate this situation.
Plan A: Best way: Rework the database to make it conducive for ISFA purposes:
1.
Resolve all misspellings of the same term. This can only be efficiently tackled by doing some light spreadsheet programming (e.g., instances where a Caterpillar-manufactured component is labeled as CAT, cat, Caterpiller, etc., along with the correct spelling,
Caterpillar). Each of these incorrect references to Caterpillar needs to be converted so that a single TOB (table of boundaries) can be applied, first at the generic level, then at the model level. Failure to resolve these instances results in
multiple TOBs, none of which is working to the best advantage. Similarly, models must undergo this same reduction to single instances. It also works the same way with lube MFR/brand (
see Figure 1).
 Figure 1. It’s important to resolve all misspellings and make the terms consistent.
Figure 1. It’s important to resolve all misspellings and make the terms consistent.
Here we’re trying to standardize on ‘all caps’ for the lube MFR, then resolve misspellings of the brand Omala. This can be done on one pass.
2.
Deconstruct fields by separating data containing multiple pieces of information so each information type can be constructively used. This need is often exposed when lubricant brands are entered/described wherein the VIS grade also is included. Let’s look at Shell/Omala again with a grade bogey included (
see Figure 2).
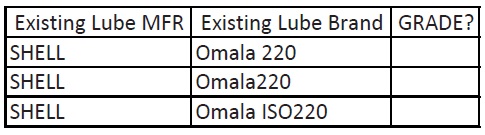 Figure 2. It is much more practical to put a brand in once, then differentiate grade in a separate column.
Figure 2. It is much more practical to put a brand in once, then differentiate grade in a separate column.
Here we’ve got three line items that are easily seen as “the same” by human inspection but not so by a computer. Any Intelligent Agent will have to guess the grade based on the incoming VIS results. Not the best situation.
Writing stripping-separation code to fix these instance types is noticeably trickier than the previous example, though it can and should be done.
This problem emanates from attempting to be too efficient by combining brand and grade. It is much more practical and efficient to put a brand in once, then differentiate grade in a separate column. There is inherently less chance for typo errors as well when this approach is adopted.
3.
Add missing data while sanitizing the database. Over years various personnel are interacting with the machinery database. Some neglect to put in component MFR or model, lube MFR or brand (or both) and even grade. This is the time to get busy and populate the holes in the database. First, it is essential when Intelligent Agents are in use; second, it’s best practice and the only sound way to ensure that ROI studies will be accurate. Third, there’s no excuse for not being thorough, and these types of omissions are no less egregious than failing to use a torque wrench properly on a bolt when such action is critical to safe operation.
Plan B if Plan A (best way) isn’t possible: Try to gather sufficient data from the extant database to construct composite TOBs that represent the disparate names and entries. For example, if we look at my July article where we looked at different VIS values that provided a giant clue, it is obvious we were not looking at like components. In that case, once the grades are resolved we can use those grade values, along with the similarity of Fe levels, to ferret out like components within the entity’s holdings, creating a “presumed” category consolidation without actually knowing it’s true. There are other clues of this nature available and, though it’s not a perfect approach, it is better than flying completely blind.
The statistical testing will almost always provide a good indication of how well you’ve estimated your consolidation. As a matter of good practice it is wise to have three components with at least four or five sets of test results before attempting to render a TOB (or else use an existing generic TOB for the presumed component until the necessary population of test data from the entity’s own components exists).
Of course, if there is already an ISFA history and corresponding data, we’re in decent shape. The resultant statistical exercise might yield data similar to Figure 3.
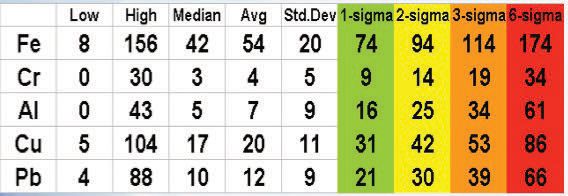 Figure 3. If there is already an ISFA history and corresponding data, we’re in decent shape.
Figure 3. If there is already an ISFA history and corresponding data, we’re in decent shape.
If there is a history longer than two years, it may be technically sounder to limit the data used to determine a TOB to an age of two years and no more, since we are most interested in what is currently occurring within the component of interest. Though data are always valuable for historical reference, they do become stale over time with respect to excursions and trending when rendering evaluations in the present.
This article’s message, in conjunction with the previous one, is:
1.
If you’re embarking on an ISFA program, take the time to sanitize your database
before you start. If that includes some rework of fields, such as adding an independent grade column, do it.
Once you’ve optimized your fields and headers, lock down your database entries so as to reject invalid values, using dropdown menus. Don’t leave the door open to spoil the good work you will have done!
2.
If you’ve been on an ISFA program for a length of time, and your database is not in conformance, it’s not too late to change course, outcome and ROI,
as you are almost certainly leaving money on the table!
 Jack Poley is managing partner of Condition Monitoring International (CMI), Miami, consultants in fluid analysis. You can reach him at jpoley@conditionmonitoringintl.com
Jack Poley is managing partner of Condition Monitoring International (CMI), Miami, consultants in fluid analysis. You can reach him at jpoley@conditionmonitoringintl.com.
For more information about CMI, visit www.conditionmonitoringintl.com.