Complexity in ISFA (in-service fluid analysis): Part XXII
Jack Poley | TLT On Condition Monitoring May 2015
Database setup is crucial to enabling accurate, nuanced evaluation.
ONCE A PROGRAM HAS BEEN ELECTED AND ESTABLISHED, it is essential to review one’s machinery database in thorough fashion. This is the first possible stumbling point and, frankly, it really sets everything else up for success, marginal gain or undetermined benefit, if any. An uninformed database or one that’s sloppily managed and under-maintained is a certain path to mediocrity, at best. I’ve never seen a database perfectly set up, but I’ve seen good ones, and those were possible because a conscious effort was given to organize, rationalize and sanitize pertinent information necessary to enable strong, effective evaluation.
Let’s recall that evaluation is the two-fold process of (1.) assessing/rating data as to magnitude of concern, (i.e., severity) and (2.) rendering pertinent, useful commentary as to what the data mean in terms of machinery (and, secondarily, lubricant) health. As such, the evaluation, as performed by a human or a software program, can be thwarted with insufficient, missing or, perhaps worse, wrong information.
Any flaw or neglected/mismanaged area in the database represents an impediment or limit as to what can be done in the way of consistently in-depth evaluation with accuracy. To belabor the point, a sample analysis has no value unless an informed evaluation has been accomplished. Everything done prior—securing and testing the sample—is simply a means to an end, that end being (a.) What is the machine’s current condition? And (b.) What action if any should be taken? In short, our goal is to have equipment operating at full capacity and generating revenue.
Let’s look at the database aspect more deeply. Last article I provided two bullets under the heading of Failure to set up the database completely and accurately. Since the second bullet was the lament that problem databases compound their consequences over time, exacerbating bad evaluations, it is only necessary to look at the first bullet’s subject, addressing it to the point where it’s no longer a threat, and there will be no omissions to be compounded, at least with respect to the database.
DATABASE FLAWS
Note: This segment doesn’t purport to dictate the kind of database to be used nor eschew the need for additional fields for machinery not mentioned herein, whether for condition monitoring purposes or otherwise—those decisions are for the entity as a whole. This segment is solely about the notion of world-class information storage, cataloging, maintenance and availability for maximized outcome, with regard to ISFA, particularly with respect to ROI.
The adage “garbage in, garbage out” works well for this exercise. One cannot do a good job of evaluation unless one knows exactly what the machine (component) type is, how it’s placed (i.e., the operating environment) and what it’s doing. There’s a lot that goes into that: manufacturer (MFR), model, application, etc.—the machine’s dossier, so to speak. It’s much the same thing as a medical history. If there are holes or bad data in the history, there are opportunities for errors in the examination.
A number of articles ago, I provided a hierarchical schematic similar to Figure 1.
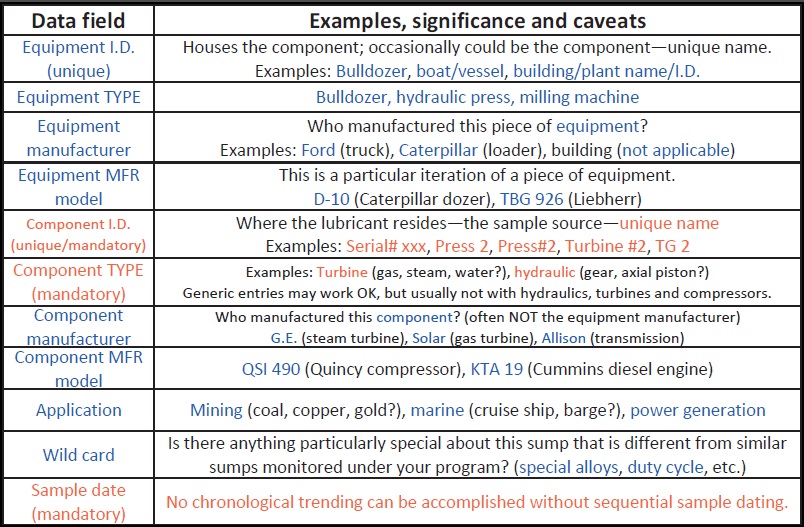 Figure 1. Hierarchical schematic table with useful fields in describing machinery.
This is the bread-and-butter set of useful fields in describing machinery. It is the backbone nomenclature foundation of a database that is used in an intelligent agent. As such it has reserved field names for particular purposes to best serve ISFA. Whether one adopts these terms or not (it is not necessary), one must map the appropriate information from the equivalent field in an existing database ready to enter ISFA. This is a trivial exercise that needs be done only a single time unless new fields are added later. Expansion, too, is not a difficult undertaking.
Figure 1. Hierarchical schematic table with useful fields in describing machinery.
This is the bread-and-butter set of useful fields in describing machinery. It is the backbone nomenclature foundation of a database that is used in an intelligent agent. As such it has reserved field names for particular purposes to best serve ISFA. Whether one adopts these terms or not (it is not necessary), one must map the appropriate information from the equivalent field in an existing database ready to enter ISFA. This is a trivial exercise that needs be done only a single time unless new fields are added later. Expansion, too, is not a difficult undertaking.
Here’s what’s missing from the previous paragraph.
1. The above fields are almost never in an extant database-in-waiting as individual fields. That fact alone bodes issues which I’ll demonstrate later.
2. There will be errors.
a. Spelling or multiple ways of representing the same MFR (or other field)
i. MFR overlap: CAT, Caterpiller, Caterpillar
ii. Grade inconsistencies: 15w-40, SAE 15w-40, 32, ISO 32
iii. Model overlap: Caterpillar 3306DIT, 3306-DIT or 3306 DIT
b. There will be simply wrong nomenclature wherein a lubricant’s brand will be called the lubricant MFR (e.g., Rotella | blank rather than Shell | Rotella)
c. There will be nonsensical entries—data in wrong fields:
i. Component type: dozer (compartment ID missing—final drive, diesel, transmission?)
ii. Component I.D. (supposedly unique): diesel engine, hydraulic.
Why is this so prevalent (trust me, it’s so)? It’s often because there was no particular provision to have ISFA as a condition monitoring tool at the time the database was populated. There was no oversight; there was an undersight. The database operated sufficiently well enough that serious consequences were avoided serendipitously, neither by intention nor omission. Humans can actually live with bad data better than computers. If a human sees CAT, Caterpiller and Caterpillar, the person is not thrown off as to the MFR—however, I’d bet on the computer once the MFR name is sanitized via consolidation into the correct name (Caterpillar, in this case) as to (eventually) performing the better evaluation. And long after the human has retired and failed to pass a good portion of his knowledge and experience along.
The previous paragraph points out one of the obstacles in advancing the database’s integrity to something approaching pristine. But the analogy is just like manual entry of repetitive data, such as one’s name and address, etc., in a computer application page when ordering tickets to an event, rather than having auto-fill from memory cache do that work. Once entered correctly, the auto-fill saves loads of time and prevents errors. Humans are not very good at that because (a.) it’s boring and easy to slough off and (b.) fingers don’t always go to the right key when typing.
So one might say a culture change must occur at the database level before a sample is even taken. Without a reasonably thorough cleaning-up, consolidating and sanitizing effort, the ISFA program is relegated to mediocrity at best (get ready for my favorite phrase): Money’s left on the table—a lot of it.
It is a wonderful thing that ISFA produces such a “ready return” so often. The off-highway industry couldn’t do without at least a partial ISFA, if for no other reason to find abrasives (dirt) in its equipment compartments via silicon and iron increases. Easy for humans to spot and deal with, too, so a positive ROI is virtually guaranteed with just this one benefit. It’s why off-highway as a composite industry is the most invested, percentage-wise, in ISFA. It’s all but guaranteed to pay off.
For the rest of the world’s compartments and sumps, it is not so easy to claim an ROI without a decent database effort and preparation.
 Jack Poley is managing partner of Condition Monitoring International (CMI), Miami, consultants in fluid analysis. You can reach him at jpoley@conditionmonitoringintl.com. For more information about CMI, visit www.conditionmonitoringintl.com.
Jack Poley is managing partner of Condition Monitoring International (CMI), Miami, consultants in fluid analysis. You can reach him at jpoley@conditionmonitoringintl.com. For more information about CMI, visit www.conditionmonitoringintl.com.